一、流程图如下
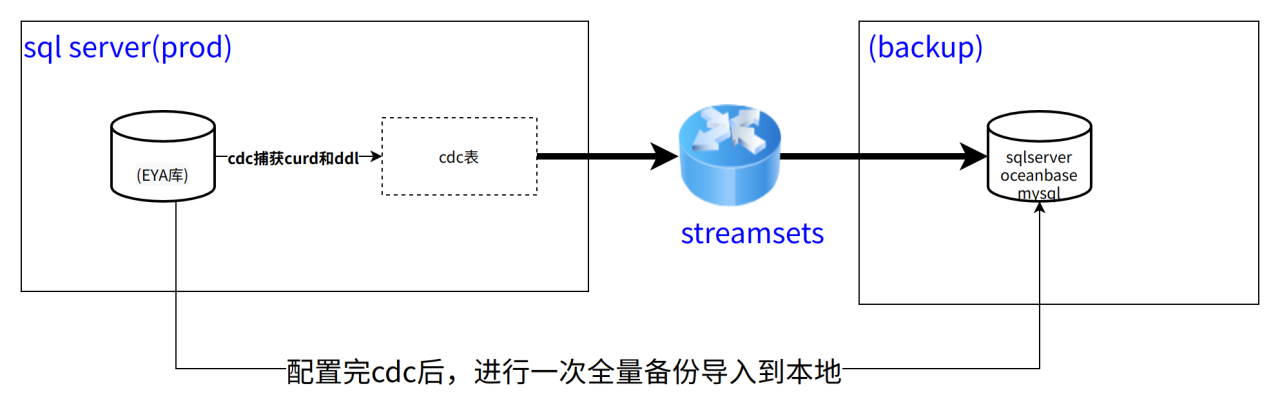
大致原理:sql server cdc可以捕获每个表的curd和ddl
注意:这个方法只能捕获带有主键或者唯一索引的表
二、sql server 配置cdc
1、开启sql server代理服务
2、数据库级启用cdc
USE xxxx
GO
EXECUTE sys.sp_cdc_enable_db;
GO
注:xxxx是要启用的数据库
执行完成后会自动在yigou数据库的系统表中生成6张表

查看哪些数据库启用了CDC:
SQL
select * from sys.databases where is_cdc_enabled = 1;
对数据库禁止CDC命令如下:
SQL
USE xxxx
GO
EXECUTE sys.sp_cdc_disable_db;
GO
3、对表级启用cdc
USE xxxx --数据库
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo', -- 架构
@source_name = N'test', -- 表名
@capture_instance = N'dbo_test', -- 按“架构_表名”即可
@role_name = NULL, -- 默认null即可
@supports_net_changes = 1 -- 是否为此捕获实例启用用于查询净更改的支持,默认值为1, 如果supports_net_changes设置为1,则必须指定index_name ,否则源表必须具有定义的主键
GO
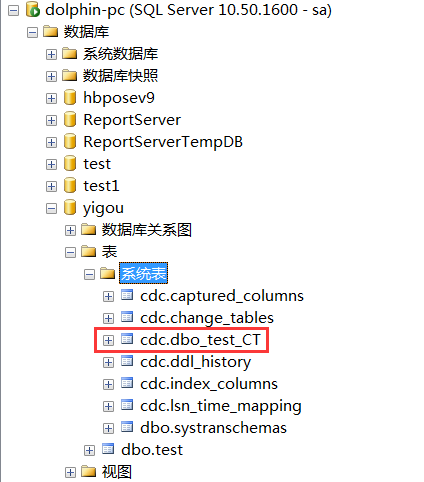
执行成功后系统表中会再多出一张表,这张表会记录所有test数据表的变更,增删改行为,增删改具体的动作对应的是__$operation字段,insert操作值为2,update操作会生成2条记录,一条是旧数据,$operation值为3,一条是新纪录,$operation值为4,delete操作__$operation值为1
SQL Server代理的作业栏下面会自动建立2个关联任务
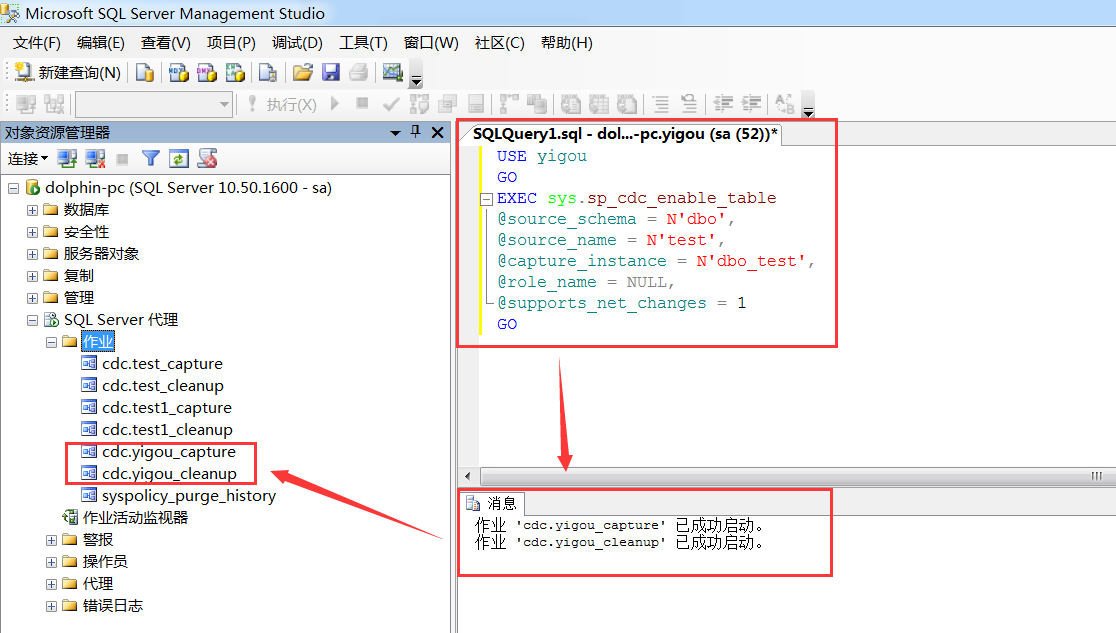
也可以用如下命令查看当前数据库下哪些表启用了CDC:
USE xxxx
GO
SELECT * FROM sys.tables where is_tracked_by_cdc=1;
GO
对test表取消CDC命令如下:
USE xxxx
GO
EXEC sys.sp_cdc_disable_table
@source_schema = N'dbo',
@source_name = N'test',
@capture_instance = N'dbo_test'
GO
4、对所有表启用/关闭cdc(需要指定数据库)
启用:
DECLARE @name NVARCHAR(50) --声明变量,需要读取的数据
DECLARE cur CURSOR --去掉STATIC关键字即可
FOR
-- 根据实际情况排除
SELECT name FROM SysObjects Where XType='U'and category in (0,32) and name NOt Like 'owe_kpi%' and name NOt Like '%_Temp'
OPEN cur --打开游标
FETCH NEXT FROM cur INTO @name --取数据
WHILE ( @@fetch_status = 0 ) --判断是否还有数据
BEGIN
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo', -- source_schemaac
@source_name = @name, -- table_name
@capture_instance = NULL, -- capture_instance
@supports_net_changes = 1, -- supports_net_changes
@role_name = NULL
FETCH NEXT FROM cur INTO @name --这里一定要写取下一条数据
END
CLOSE cur --关闭游标
DEALLOCATE cur
关闭:
DECLARE @name NVARCHAR(50) --声明变量,需要读取的数据
DECLARE cur CURSOR --去掉STATIC关键字即可
FOR
-- 根据实际情况排除
SELECT name FROM SysObjects Where XType='U' and uid='1'and category =0
OPEN cur --打开游标
FETCH NEXT FROM cur INTO @name --取数据
WHILE ( @@fetch_status = 0 ) --判断是否还有数据
BEGIN
EXEC sys.sp_cdc_disable_table
@source_schema = 'dbo', -- source_schemaac
@source_name = @name, -- table_name
@capture_instance = 'all'
FETCH NEXT FROM cur INTO @name --这里一定要写取下一条数据
END
CLOSE cur --关闭游标
DEALLOCATE cur
5、修改清除作业执行周期和每次清理CDC表行数据量
参考:
> http://blog.itpub.net/22996654/viewspace-2912741/
> http://www.caotama.com/1939891.html
默认4320(分钟)后清除捕获的增量数据,您可以修改增量数据的保留时间。例如,如下命令将保留时间修改为129600(分钟)。
```SQL
-- 1.查询job情况
EXEC sys.sp_cdc_help_jobs;
-- 字段说明:http://blog.itpub.net/22996654/viewspace-2912741/
-- 2.更改清除作业执行周期
EXECUTE sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention = 129600;
-- 更改每次清理的数据量
EXECUTE sys.sp_cdc_change_job
@job_type = N'cleanup',
@threshold = 1000;
--仅在使用 sp_cdc_stop_job 停止作业并使用 sp_cdc_start_job
-- 重新启动该作业后,对该作业所做的更改才会生效
EXECUTE sys.sp_cdc_stop_job
@job_type = N'cleanup'
EXECUTE sys.sp_cdc_start_job
@job_type = N'cleanup';
6、修改捕获作业读取事务日志的周期
默认时间间隔为 5(秒),当间隔时间越长,增量数据记录到变更表的时间就可能越长,因此您可以适当调整周期间隔时间。例如,如下命令将周期间隔时间修改为 1(秒)。
EXECUTE sys.sp_cdc_change_job
@job_type = N'capture',
@pollinginterval = 1;
-- 重新启动
EXECUTE sys.sp_cdc_start_job
@job_type = N'capture';
三、streamsets部署
部署版本:3.22.3
下载启动即可:bin/streamsets dc &
1、配置pipeline
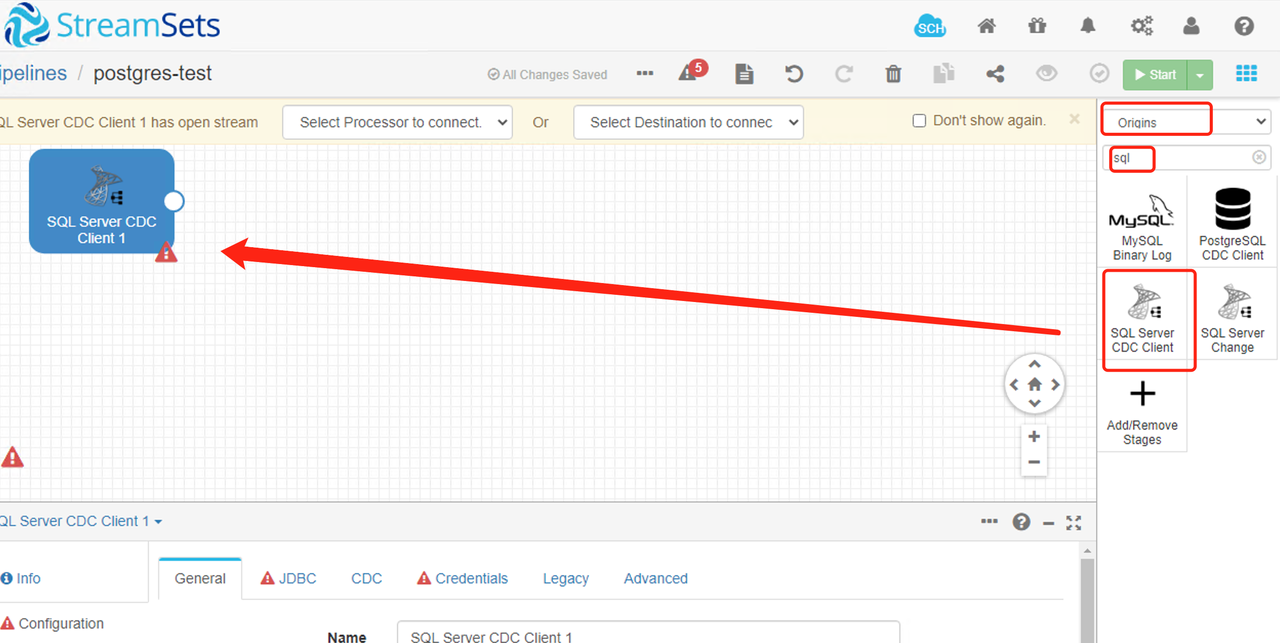
2、jdbc配置
这里主要配置一些JDBC相关信息,需要注意的地方不多,包括多线程之类的参数按需配置即可
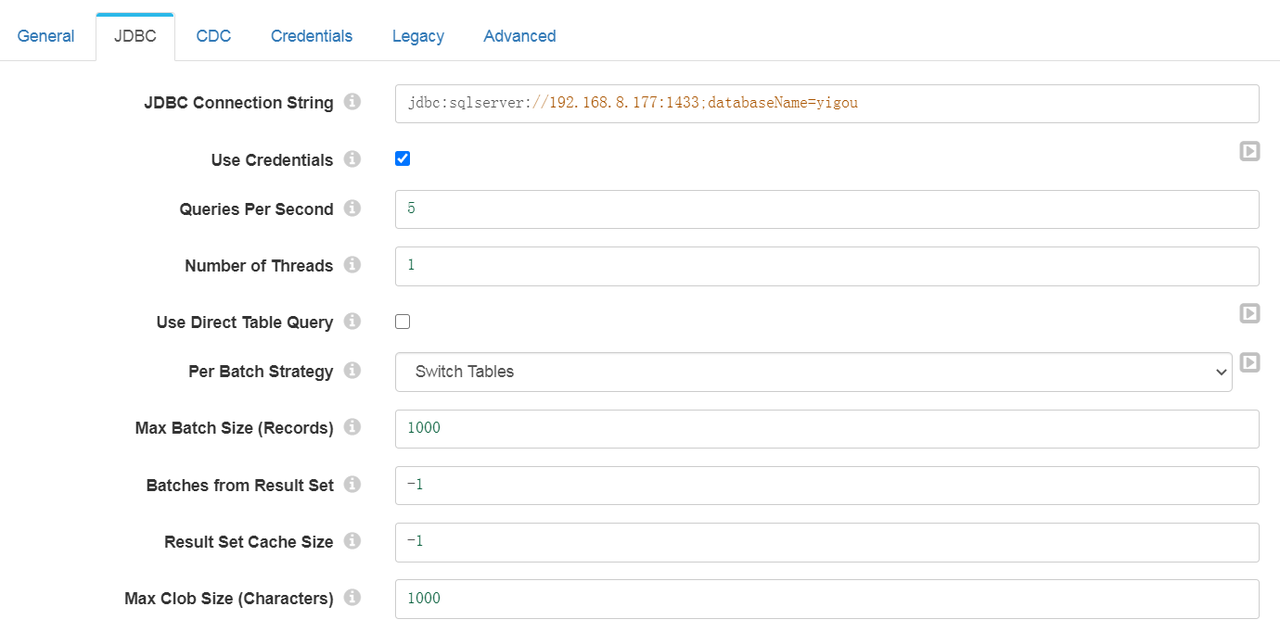
注意:不要勾选“Enable Schema Changes Event ”,那个还有bug,会导致pipeline启动异常
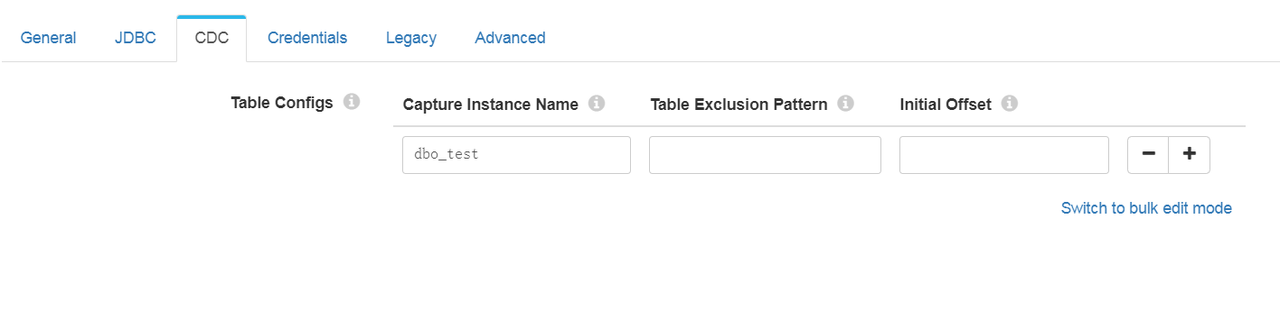
3、cdc配置
4、Credentials
填写数据库账号密码即可
5、其它配置可以按需即可
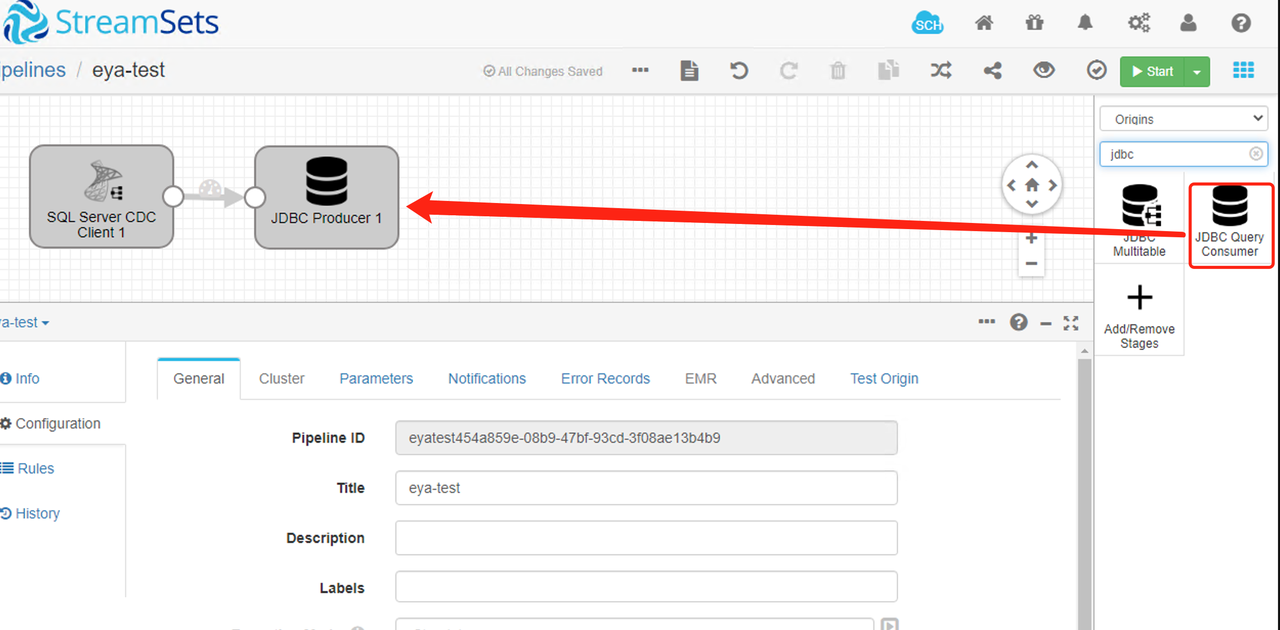
6、实时同步数据到目标sql server
新增jdbc producer
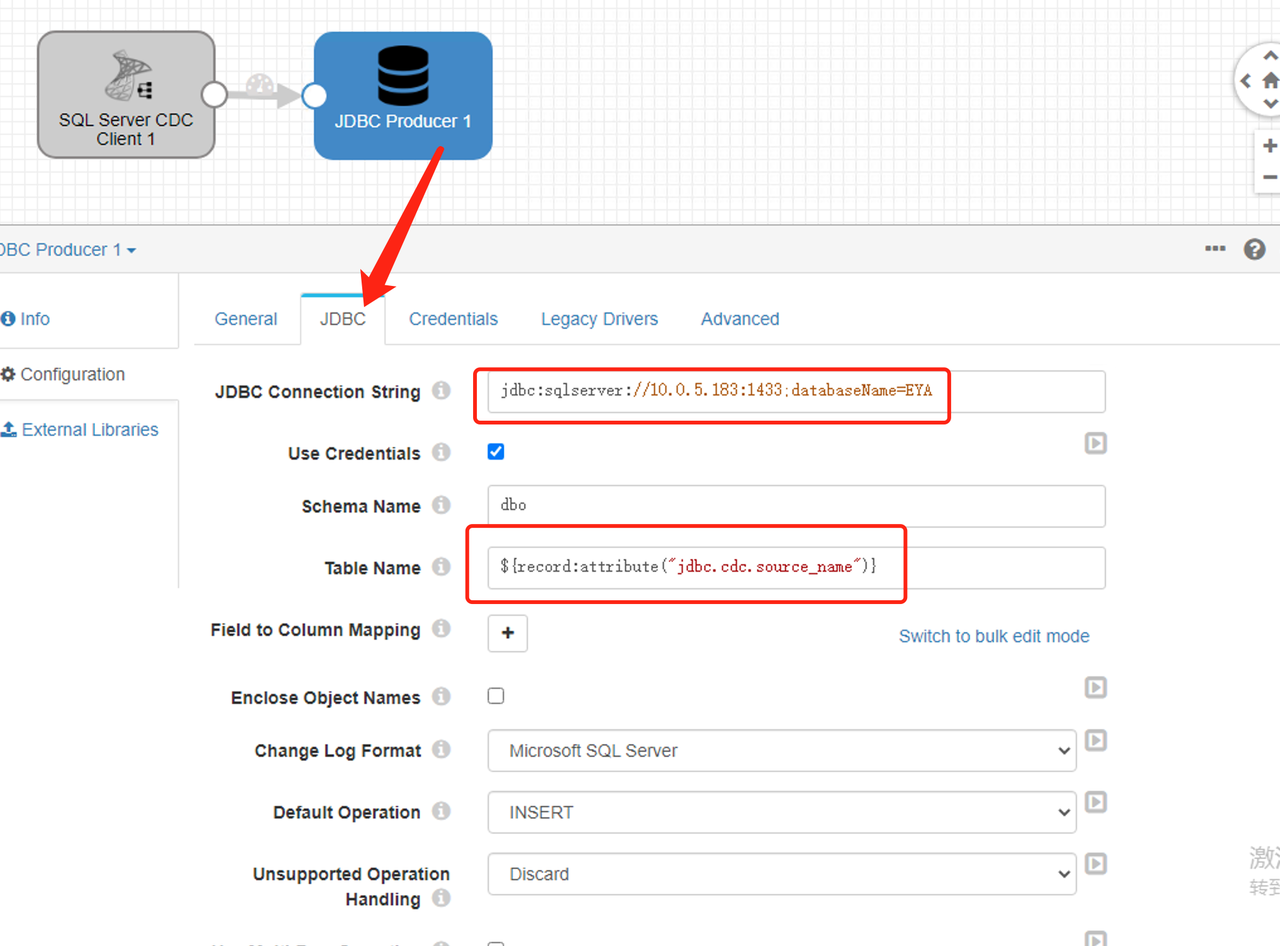
四、特殊处理:
- timestamp转字符串
- owe_Inventory.AIOSKU 转字符串
五、sql server 转mysql特殊处理
date->date